
In partnership with
Hi!
Welcome back to AIMedily.
I don’t know about you, but this year is moving incredibly fast. I can’t believe it’s already May.
This week was graduation week at the University of Michigan, and the Robotics department celebrated with a robot parade, including the lab where I work. You can check it out here.
Now, let’s get into today’s issue.
🤖 AIBytes
Researchers tested OpenAI’s o1 model against physicians in 6 clinical reasoning experiments. These included published teaching cases and real emergency department patients.
They compared diagnosis, test selection, management reasoning, and second-opinion performance using real clinical data.
🔬 Methods
The model was tested on published diagnostic and management cases and on 76 real emergency department cases.
In the emergency department study, o1, GPT-4o, and 2 attending physicians each gave differential diagnoses.
Two other attending physicians scored the answers without knowing whether they came from a model or a physician.
📊 Results
In the published diagnosis cases, o1 often included the correct or a very close diagnosis.
In the NEJM case series, it included the correct diagnosis in 78.3% of cases. When very close answers were also counted, this increased to 97.9%.
For next-test selection, o1 chose the correct test in 87.5% of cases.
In structured reasoning tasks, o1 outperformed GPT-4 and physician comparison groups in several experiments. For example, in the NEJM Healer cases, it achieved a perfect score in 78 of 80 cases.
In the emergency department study, o1 identified the exact or very close diagnosis in 67.1% of cases at triage, 72.4% during physician evaluation, and 81.6% at hospital or ICU admission.
It performed better than both attending physicians at each stage.
🔑 Key Takeaways
In this study, o1 outperformed physician baselines on several text-based clinical reasoning tasks.
The biggest gap appeared early in the emergency department, when information was limited and decisions were urgent.
This does not mean the model is ready for independent clinical use. The authors call for prospective trials, monitoring, and safer clinician-AI integration.
The study was limited to text-based tasks and focused mainly on internal medicine and emergency medicine, so the results may not apply to all specialties or real-world multimodal care.
🔗 Brodeur PG, Buckley TA, Kanjee Z, et al. Performance of a large language model on the reasoning tasks of a physician. Science. 2026;392(6797). doi:10.1126/science.adz4433
Researchers built APOLLO, a multimodal foundation model that turns a patient’s full medical record into one patient representation.
It was trained on 25.3 billion medical events from 7.2 million patients and tested across disease prediction, disease progression, treatment response, adverse events, hospital outcomes, and patient retrieval.
🔬 Methods
APOLLO used structured data, clinical notes, reports, and some images from one large U.S. health system.
The model was tested on 322 tasks.
📊 Results
APOLLO outperformed the age-sex baseline in:
74 of 95 new disease tasks
53 of 78 disease progression tasks
30 of 59 treatment response tasks
12 of 17 adverse event tasks
9 of 12 hospital operations tasks
Strong examples included:
Schizophrenia risk: 0.92 vs 0.65
Acute myocardial infarction risk: 0.82 vs 0.68
Heart failure risk: 0.88 vs 0.77
Trastuzumab survival in breast cancer: 0.93 vs 0.66
Acute kidney injury after NSAIDs: 0.91 vs 0.80
The model also supported patient retrieval using full records, text, or image queries.
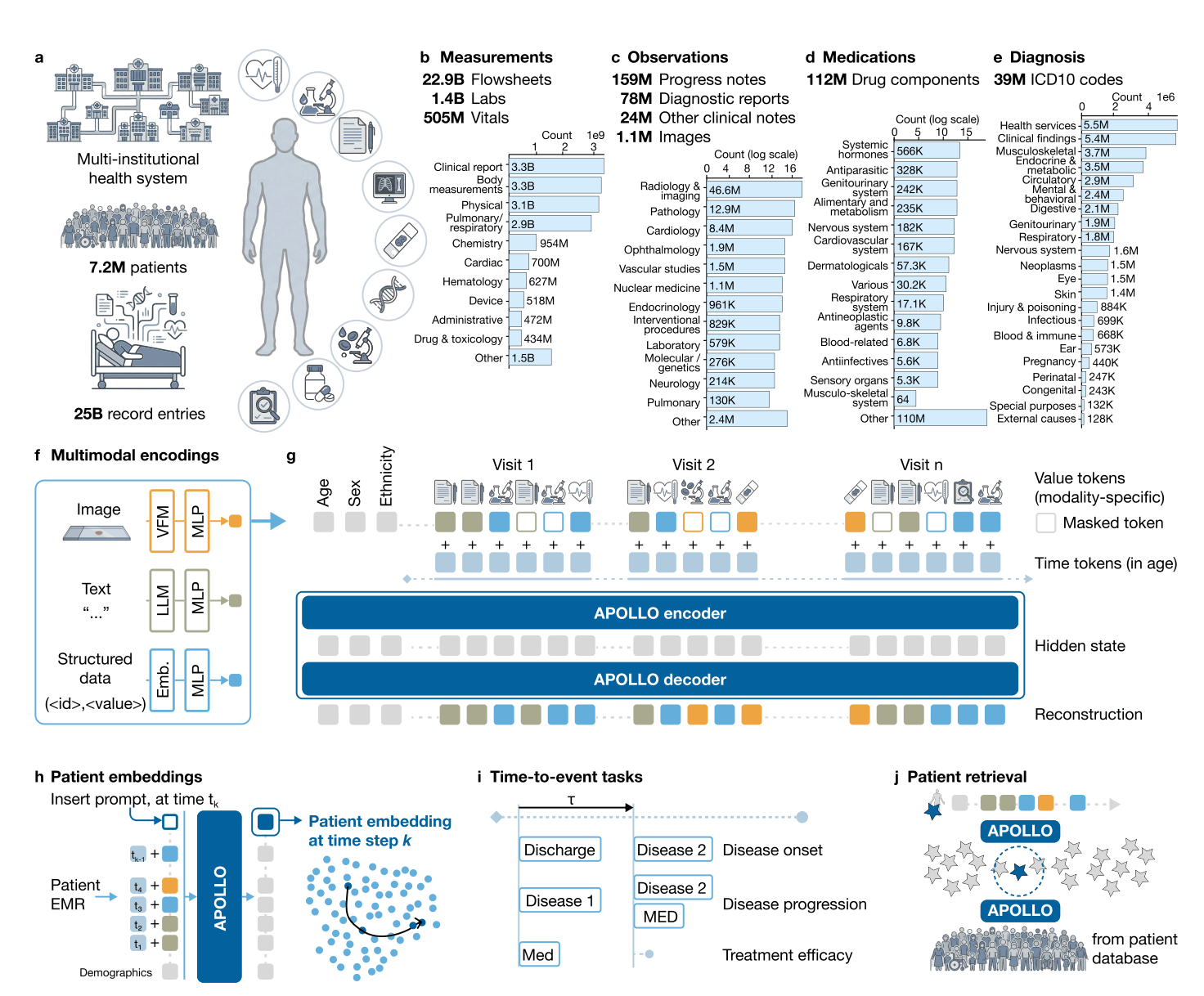
Image from original paper

🔑 Key Takeaways
APOLLO was built as a general patient model, not for one disease only.
Its main strength is that it uses the whole medical record, not just structured EHR data.
The results are promising, but this was still one health system, so outside validation is still needed.
The model is associational, not causal. It predicts risk, but it does not show which treatment is best.
🔗 Zhang A, Ding T, Wagner SJ, et al. A multimodal and temporal foundation model for virtual patient representations at healthcare system scale. arXiv. 2026. doi:10.48550/arXiv.2604.18570
🦾TechTools
Uses AI and retinal scans to estimate cardiometabolic risk quickly and without radiation.
Its platform includes Dr. Noon CVD, which helps assess future cardiovascular disease risk from a retinal image.
Designed for real clinical workflows, with results available in minutes.
AI-enabled ECG platform that helps identify patients at risk for hidden cardiovascular disease.
Includes FDA-cleared tools for atrial fibrillation risk and low ejection fraction detection.
Built to fit into existing ECG and EHR workflows.
📈 Productivity Tool of the Week:
AI browser that can search the web and generate one clear answer instead of making you open many tabs.
Includes features like Browse for Me, page summarization, reader mode, and translation.
Useful for quickly comparing tools, reading articles faster, and reducing research clutter on mobile.
🧬AIMedily Snaps
OpenEvidence collaborates with NCCN to integrate canonical oncology treatment angowithms at the Point-of-Care (Link).
Eric Topol: The Paradox of Medical AI Implementation (Link).
Google Deepmind: Enabling a new model for healthcare with AI co-clinician (Link).
Stanford AIMI session: Multimodal foundation models for precision oncology (Link).
AI Tool that Estimates Biological Age from Face Photos Could Serve as Prognostic Biomarker for Cancer (Link).
🧪Research Signals
Nature: Towards generalizable AI in medicine via Generalist–Specialist Collaboration (Link).
NPJ: The absence of full lifecycle risk management for AI-based medical devices in radiology (Link).
Nature: Show us the evidence for the value of medical AI (Link).
CheXthought: A global multimodal dataset of clinical chain-of-thought reasoning and visual attention for chest X-ray interpretation (Link).
JMIR: Clinical AI is Not (Yet) Trustworthy—But It Could Be (Link).
NEJM: A Typology of Generative Health Care AI — Definitions and Policy Implications (Link).
🧩TriviaRX
Which procedure was performed in 1667, briefly seemed successful, and was then banned for years?
A) Cesarean section
B) Smallpox inoculation
C) Blood transfusion
D) Appendectomy
Now, the answer from last week’s TriviaRX ✅ B) Smallpox
Smallpox became the first human disease eradicated worldwide through vaccination, culminating in WHO’s eradication declaration in 1980.
That’s it for today.
As always, thank you for taking the time to read.
You’re already ahead of the curve in medical AI — don’t keep it to yourself. Forward AIMedily to your colleagues who’d appreciate the insights.
Until next week.
Itzel Fer, MD PM&R
Forwarded this email? Sign up here
P.S. Enjoying AIMedily? 👉 Write a review here (it takes less than a minute).





