
In partnership with
Receive Honest News Today

Join over 4 million Americans who start their day with 1440 – your daily digest for unbiased, fact-centric news. From politics to sports, we cover it all by analyzing over 100 sources. Our concise, 5-minute read lands in your inbox each morning at no cost. Experience news without the noise; let 1440 help you make up your own mind. Sign up now and invite your friends and family to be part of the informed.
Hi!
Today is LLM Friday.
A day focused only on Large Language Models.
As I mentioned on Wednesday, this week I was in Chicago attending the American Congress of Rehabilitation Medicine (ACRM) conference.
Planning a trip like this is always a bit overwhelming — balancing work, family, and travel logistics isn’t easy. Do you ever feel the same way?
But once I’m there, I always remember why it’s worth it. It’s inspiring to connect, learn, and share ideas with amazing people who are kind and generous with their knowledge.
Now, let’s dive into today’s newsletter.
✨LLMs
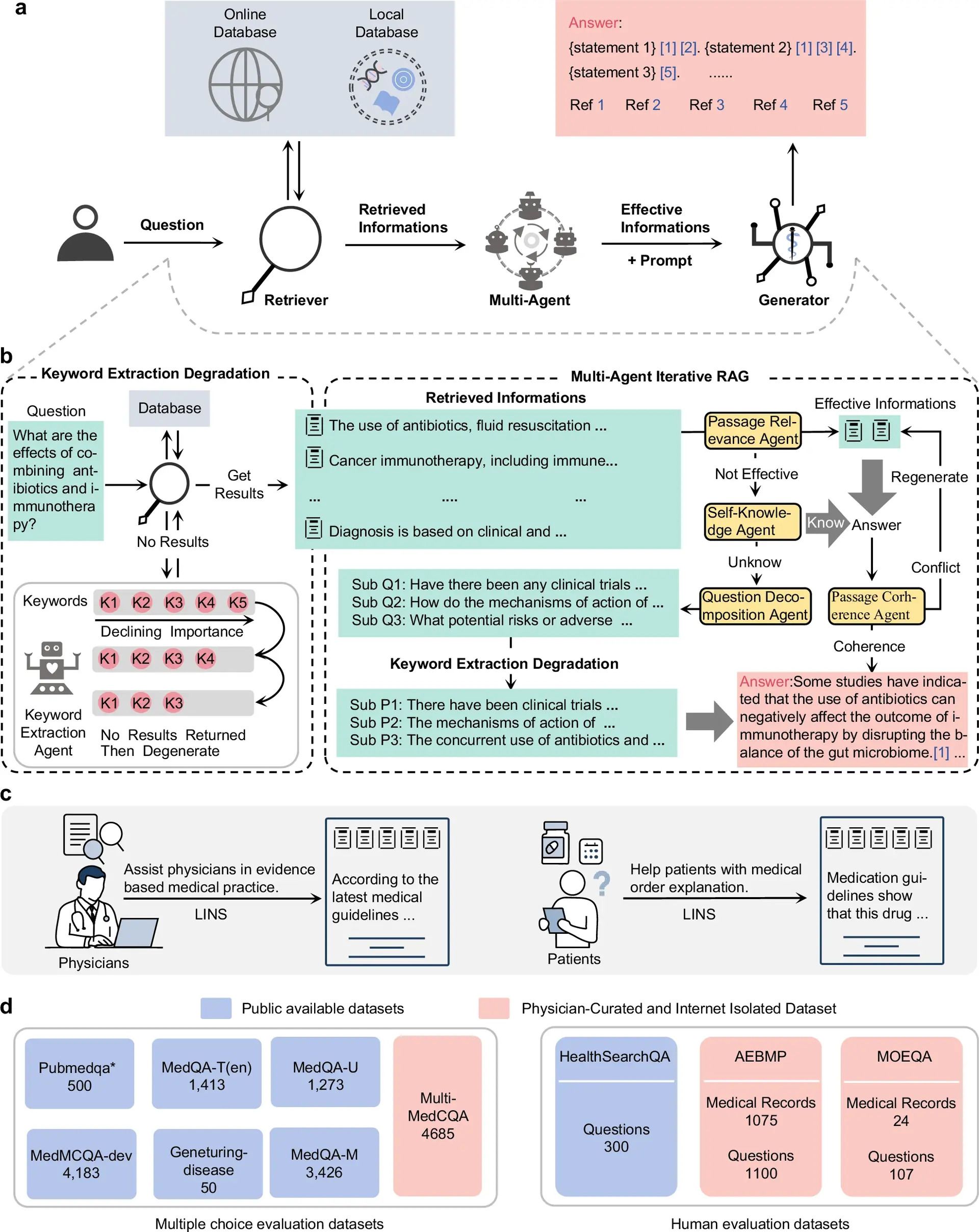
Researchers introduced LINS (Large-language-model Integration and Supervision) — a framework that links LLMs to real-time medical evidence to make responses more accurate, transparent, and verifiable.
🔬 Methods
LLMs tested: GPT-4o-mini, GPT-4o, o1-mini, o1-preview, Llama3.1, Qwen2.5, Gemini-1.5-flash, and Gemini-1.5-pro.
This LINS system uses 4 modules:
Database
Retrieval with KED (Keyword Extraction Degradation) for precise search
by refining key terms.
Multi Agent Retrieval-augmented generation (MAIRAG): AI agents to fact-check and cross-validate.
Generator producing evidence-linked answers.
To test the system, they used 6 public datasets, but also developed these Datasets:
Multi-MedCQA: 4,685 multiple-choice clinical questions made by 50 physicians.
AEBMP: Open-ended questions crafted by physicians based on real clinical data.
MOEQA questions from a patient’s perspective.
📊 Results
Across 15,530 test questions.
LINS improves response credibility by over 40 % (p < 0.001) vs baseline LLMs.
87 % of resident physicians reported LINS improved evidence-based reasoning.
90 % of patients found its explanations of medical orders clear and trustworthy.
83 – 95 % of accuracy.
Evidence traceability:
Citation precision 76 %
Factual correctness 98 %

🔑 Key Takeaways
LINS adds real-time evidence retrieval, making their answers more transparent and reliable.
Multi-agent filters unreliable data and ensures every response is supported by traceable evidence.
Demonstrated value for both clinicians and patients.
Represents a scalable, evidence-based framework for safer and more credible medical AI systems.
🔗 Wang S, Zhao F, Bu D, et al. LINS: A general medical Q&A framework for enhancing the quality and credibility of LLM-generated responses. Nature Communications. 2025; 16: 9076. doi:10.1038/s41467-025-64142-2
🦾TechTool
15 tools in 1. Cabina lets you use ChatGPT, Claude, Gemini, Mistral, Midjourney and others in one clean interface—no need to switch tabs or lose track of context.
You can compare how models reason. Run the same prompt across different LLMs and see which one is more accurate.
You can generate text, image, video, and code.
Next week, we will continue exploring how to prompt to get what you need, and will share with you an AI tool I love. Stay tuned.
🧬 AIMedily Snaps
Too much social media gives AI chatbots ‘brain rot’ (Link).
OpenAI Foundation will invest $25B on healthcare (Link).
That’s all for today.
You’re already ahead of the curve in medical LLMs — don’t keep it to yourself.
Share AIMedily with a colleague who’d appreciate the insights.
Thank you!
Until next Wednesday.
Itzel Fer, MD PM&R
Forwarded this email? Sign up here
PS: Enjoying AIMedily? Your short review helps strengthen this community.
👉 Write a review here (it takes less than a minute).